
Accurate buyer context is primarily a data problem. The models are rentable; the outcome-linked behavioral data underneath is not. Here’s what the data actually requires — and why assembling that combination confers a head start measured in years, not quarters.
If accurate Website Buyer Context is as valuable as the results suggest — surfacing invisible pipeline, separating buyers from browsers, making every downstream system more accurate — the obvious question is why a well-funded competitor can’t simply build it.
The answer is structural, and it starts with reframing the problem. Website Buyer Context is primarily a data problem, not a modeling problem. Anyone can rent a frontier model and an agent framework; those are converging and confer no durable edge. What does not commoditize is the training data underneath, and in this domain the fidelity and structure of that data sets the ceiling on what any model can do. The hard part isn’t the algorithm. It’s assembling the right data — and the right combination is genuinely rare.

It starts with data that’s hard to assemble. Most models learn from engagement. Lift AI learned from revenue.
Lift AI didn’t begin as a model. It began as a business that was only paid when it was right. From 2005 to 2020, our team operated a commission-based sales-as-a-service business — compensated solely on verified revenue we generated for enterprise clients. Every conversion was tracked to the decimal and audited by clients whose own payouts depended on the accuracy. That produced billions of website journeys across industries, tied directly to hundreds of millions of commission-validated conversions.
That compensation structure is the forcing function competitors lack. Payment was the audit — a label was true only if a client paid on it. And because we were paid on incremental revenue, we had to prove our engagement caused the outcome, not merely correlated with it. The result is causal-grade, audit-validated labels; a subscription vendor, paid whether its predictions are right or wrong, has no equivalent pressure, so its labels stay soft.
That foundation has three properties that are individually hard to obtain and exceptionally hard to obtain together:
Commission-validated outcome labels. Audit-grade revenue truth — outcomes proven to the decimal because real money changed hands on them — not CRM dispositions, MQL labels, or marketing-attributed proxies. For supervised learning, the labels are the part that matters most, and these are the cleanest class that exists for the problem.
The full behavioral distribution. Trained on the entire visitor population — buyers and the vast majority of non-buyers, anonymous and identified — not just the 1–3% who engaged via form or chat. A model that only sees the engaged minority inherits a selection bias it cannot escape, and can never score the anonymous population where much of the pipeline lives.
Multi-industry breadth and continuity. Patterns that hold across industries and verticals, B2B and B2C, accumulated over fifteen years. Breadth reduces the vertical bias a single-platform builder inherits from its own customer base; continuity is what let the model learn how buying behavior maps to outcomes in the first place.

What modern AI changes — and what it doesn’t
It’s fair to ask whether modern technique erases this advantage. Foundation models, self-supervised and transfer learning, synthetic data, and new signal streams — DOM structure, session graphs, mouse dynamics, in-session context — have genuinely expanded usable signal and reduced how much labeled data a model needs to learn a representation. The 2005–2020 period was not a permanently sealed golden age; total usable signal has grown, and a good team today has tools a team in 2015 did not.
But these techniques learn representations; they don’t manufacture ground-truth outcome labels. You can synthesize a plausible behavioral sequence. You cannot synthesize the fact that a specific visitor went on to generate audited, closed revenue. For a rare-event prediction problem, label fidelity is the binding constraint — and it’s exactly the part technique can’t conjure from nothing. Modern AI raises the floor for everyone, which is good for the problem. It does not erase an advantage rooted in a large, clean, full-distribution set of verified outcomes.
Why starting today means years of disadvantage
A well-resourced team starting now would face several structural headwinds at once:
- Cold start. Without an existing base of verified outcome labels, the model has nothing to learn the behavior-to-revenue mapping from — the single hardest thing to bootstrap. It takes years of live deployment to accumulate enough labeled outcomes to reach reliable accuracy.
- Selection bias. A builder who starts from their own product’s data only sees the visitors who engaged inside their product, and inherits a biased sample that systematically misses the anonymous majority.
- Vertical narrowness. A single-platform builder learns one industry’s patterns first, and generalizes slowly across the others.
- Instrumentation depth. Reading behavior before any form, chat, or CRM event requires observing the full session, not just product events — which for most platforms means re-architecting how they instrument visitors in the first place.
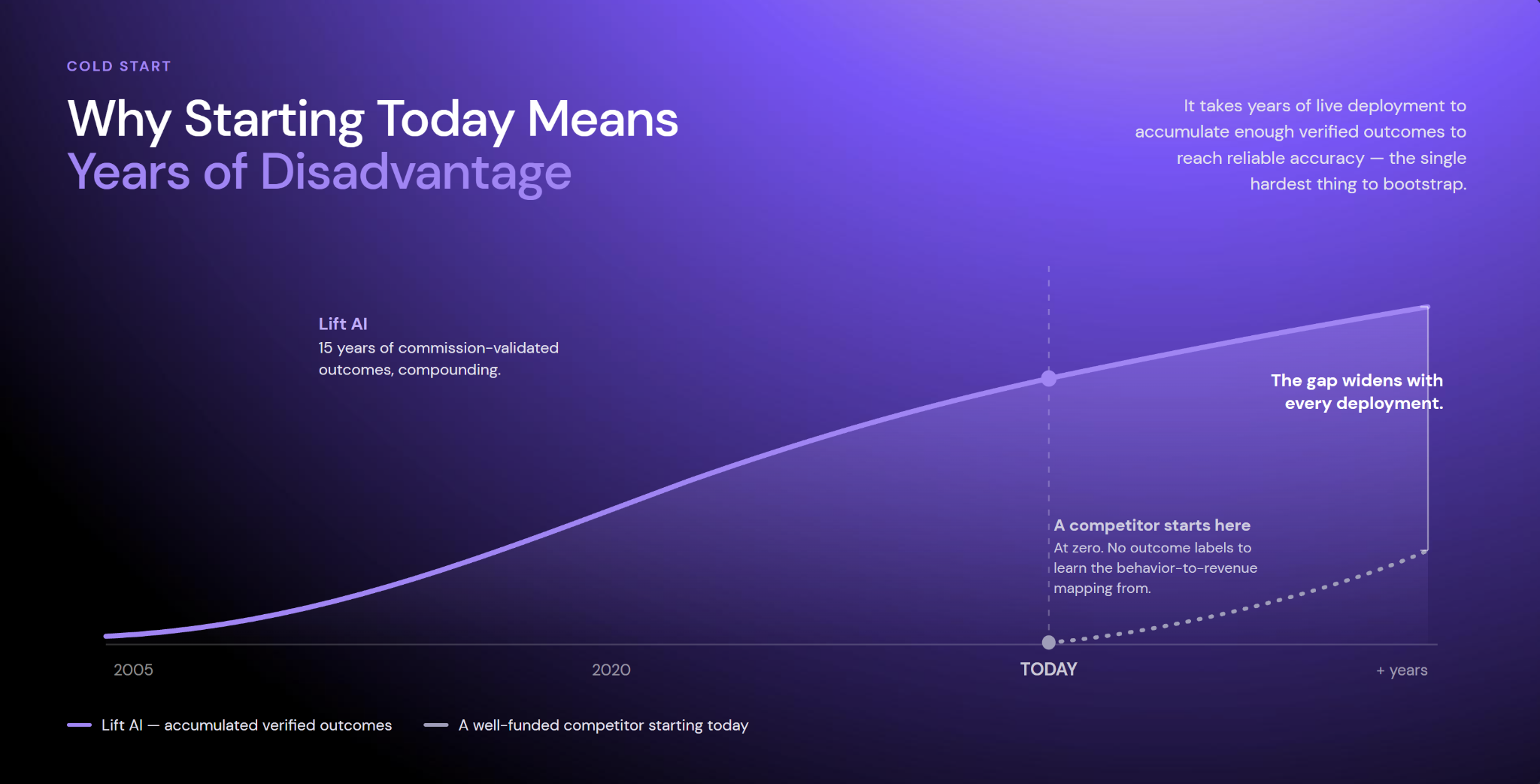
The honest version of the moat
The moat is structural, not temporal. This is not an uncrossable moat. A determined, well-funded competitor could build something directionally similar over years, and the largest data owners — Google, Meta, Salesforce, HubSpot — have enormous behavioral datasets. The point is narrower and more durable: assembling this specific combination is exceptionally hard, and would require adopting a business model almost no one will run, for years. Scale alone doesn’t close it, because scale is not the same as fit — a vast dataset that isn’t linked to the full distribution of verified outcomes can’t do what this problem requires.
And the advantage is current, not archived. The historical data is the foundation — the head start — not the product. Every Lift AI deployment generates first-party behavioral data unique to that customer and feeds a continuous reinforcement loop that keeps the model calibrated to how buyers behave now. Over time the training distribution becomes majority-modern data, by design: that’s how the advantage stays relevant while the cold-start barrier keeps protecting it. History gave us the head start; the live pipeline keeps it from aging.
Not all moats are equal
Using Richard Dulude’s Context Moats framework, most intent solutions sit in shallower tiers — built on public or lightly proprietary signals that competitors can also acquire. Lift AI is anchored in a deeper Behavioral context tier: patterns learned from observed behavior mapped to verified outcomes, which is far harder to source. That depth, combined with fifteen years of temporal advantage and continuous reinforcement, is where the defensibility actually lives — not in any single signal or feature.

What this is worth in practice
The proof is in production outcomes, not the moat argument. Across deployments, accurate probability surfaces anonymous buyers other tools miss, separates buyers from browsers within identified accounts, feeds smarter routing to agents and reps, and improves advertising efficiency. At Boomi, replacing page-based chat triggers with Website Buyer Context drove a 23.4× closed-won revenue multiple over 18 months — not from smarter agents, but from better targeting of the same execution.
Models, agents, and execution layers are commoditizing fast. What stays scarce is high-fidelity, outcome-linked behavioral context that can’t be scraped or synthesized. Lift AI’s combination of a hard-to-assemble historical foundation, continuous reinforcement, and real-time deployment creates a widening lead in the one layer that matters most as execution becomes table stakes: reliable buyer probability.
It is not impossible for a determined competitor to build toward something similar over many years. But it is exceptionally difficult to match the accuracy, generalization, and proven full-funnel impact in any near-term horizon. The production performance is the product. The hard-to-assemble dataset and compounding system behind it is the head start — and it widens with every deployment.
Lift AI is the Website Buyer Context layer for the GTM stack. It interprets each visitor's behavior in real time — known and anonymous — and resolves it into a Probability Score (0–100) that tells you how likely they are to buy, with over 85% accuracy.



