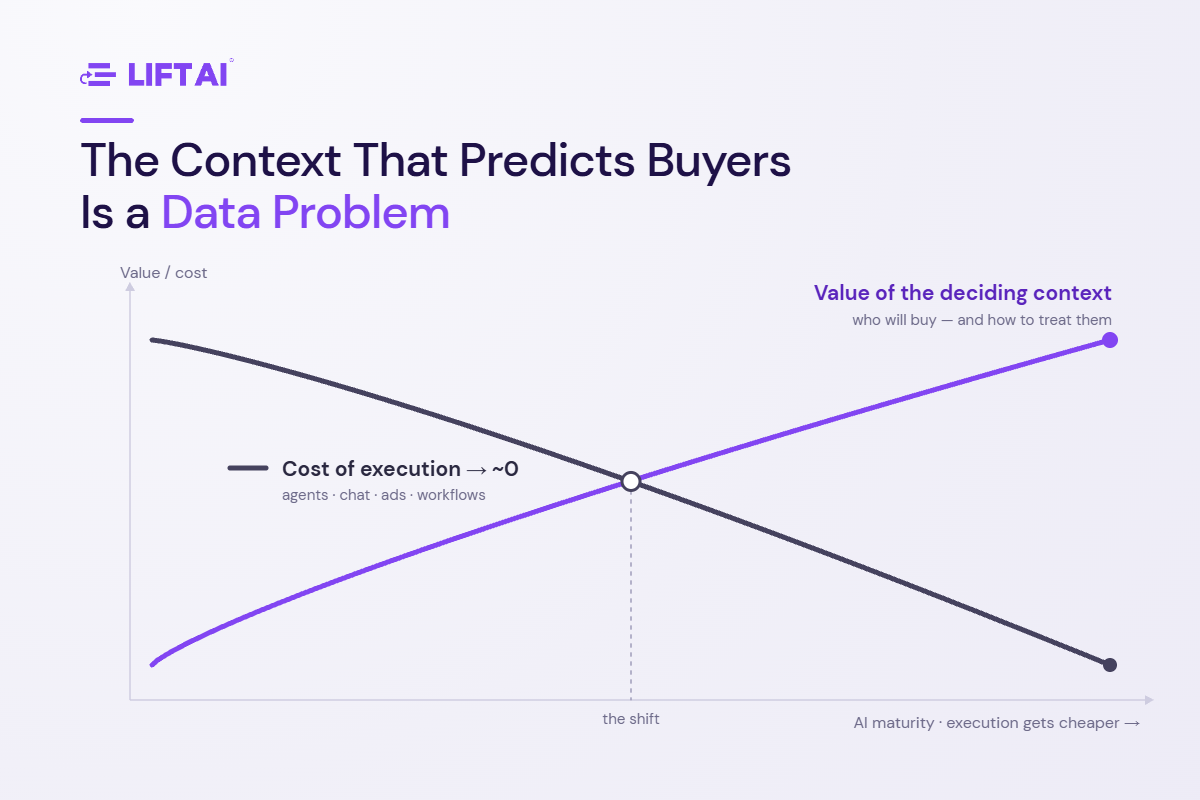
As AI commoditizes GTM execution, the advantage becomes the quality of the context that decides where execution is applied. But predicting who will buy is primarily a data problem — and the combination of data it requires is rare, compounding, and harder to assemble than it looks.
The shift that resets the GTM question
Every serious investor in GTM is now underwriting the same bet, whether they frame it this way or not: that some company will own the layer that tells AI what to do.
The reason is a shift almost no one disputes. AI has made execution abundant and nearly free. Agents, chat, advertising, and workflow automation run continuously, autonomously, and at marginal cost. Ninety percent of organizations are running AI in their go-to-market motion. Only about 5% report meaningful ROI from it (Boston Consulting Group, 2025).
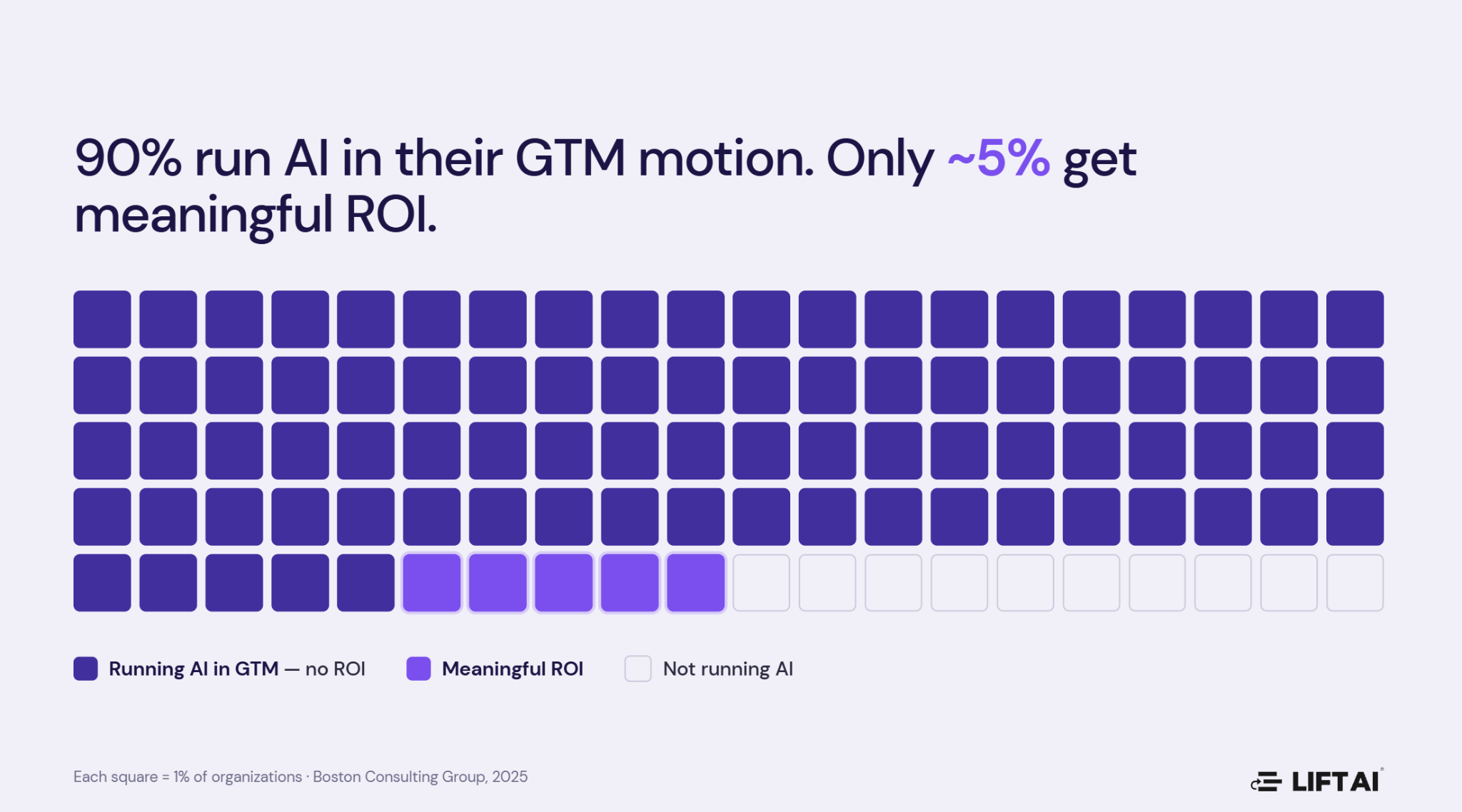
The instinctive reading of that gap is that the models still aren’t good enough. That reading is wrong, and the error matters because it sends capital toward the wrong layer. The models are remarkable. The execution is remarkable. The problem is that execution is being applied against context that was never accurate to begin with — and when you scale flawed targeting with cheap, infinite execution, you don’t get better outcomes. You get more waste, faster.
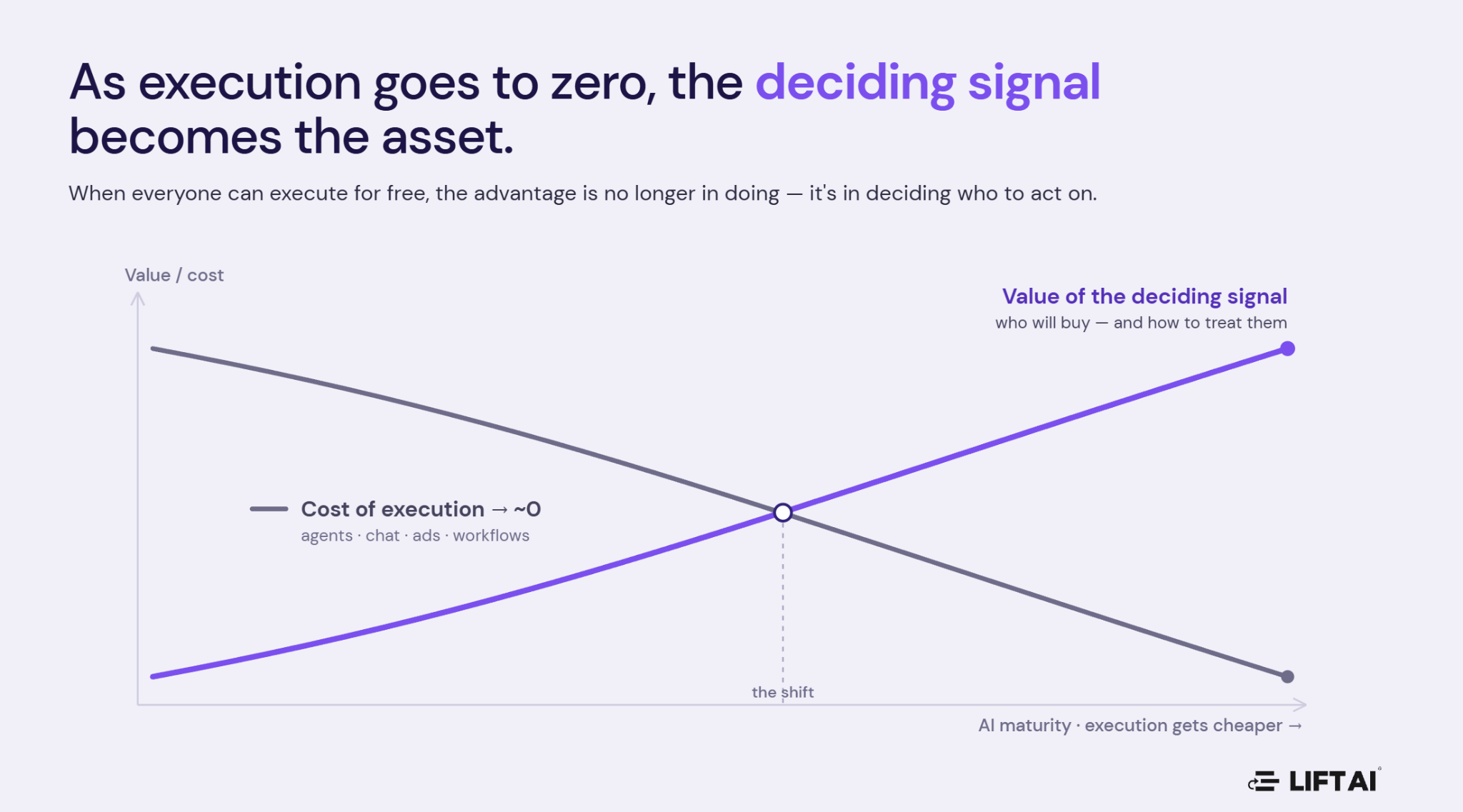
So the binding constraint moves. When execution is commoditized, the advantage is no longer in doing — it is in deciding what to do. Every meaningful GTM decision reduces to two questions: how likely is this person to buy, and how should we treat them? The quality of the answer now governs the return on every dollar of execution spend downstream. That answer is the scarce asset, and almost no one in the stack actually has it.
The thesis: predicting buyers is primarily a data problem
Predicting buyer probability is primarily a data problem, not a modeling problem. That word — primarily — matters, because the strong version of this claim is not “models don’t matter.” Models matter enormously, and they are improving fast. The claim is that model architecture is the layer that is converging and commoditizing, while the outcome-linked data underneath is the layer that is not. The same frontier models and agent frameworks are available to every company willing to rent them, which is precisely why they confer no durable advantage. What does not commoditize is the training data: in this domain, the fidelity and structure of the data you learn from sets the ceiling on what any model can do with it.
This is not a controversial position to anyone who builds machine learning systems. For a rare-event prediction problem — for example, where buyers represent a small minority of website traffic and the signals to predict them are subtle — the quality and structure of the labeled data dominates incremental architecture choices. The interesting question is not whether data quality matters. It is whether anyone has assembled the right data for this specific problem. Most of the category has not. They train on what is easy to capture: engagement signals, identity graphs, third-party intent feeds, CRM dispositions. Each describes something about a prospect. None is structured as behavior linked to verified revenue outcomes across the full population of visitors — which is what the problem actually requires.
That gap, between what most vendors train on and what the problem demands, is the entire investment thesis.
Why the context category trains on the wrong data
Two assumptions are baked so deeply into the GTM stack that almost no one questions them, and both lead vendors toward the wrong training data when it comes to predicting buyers.
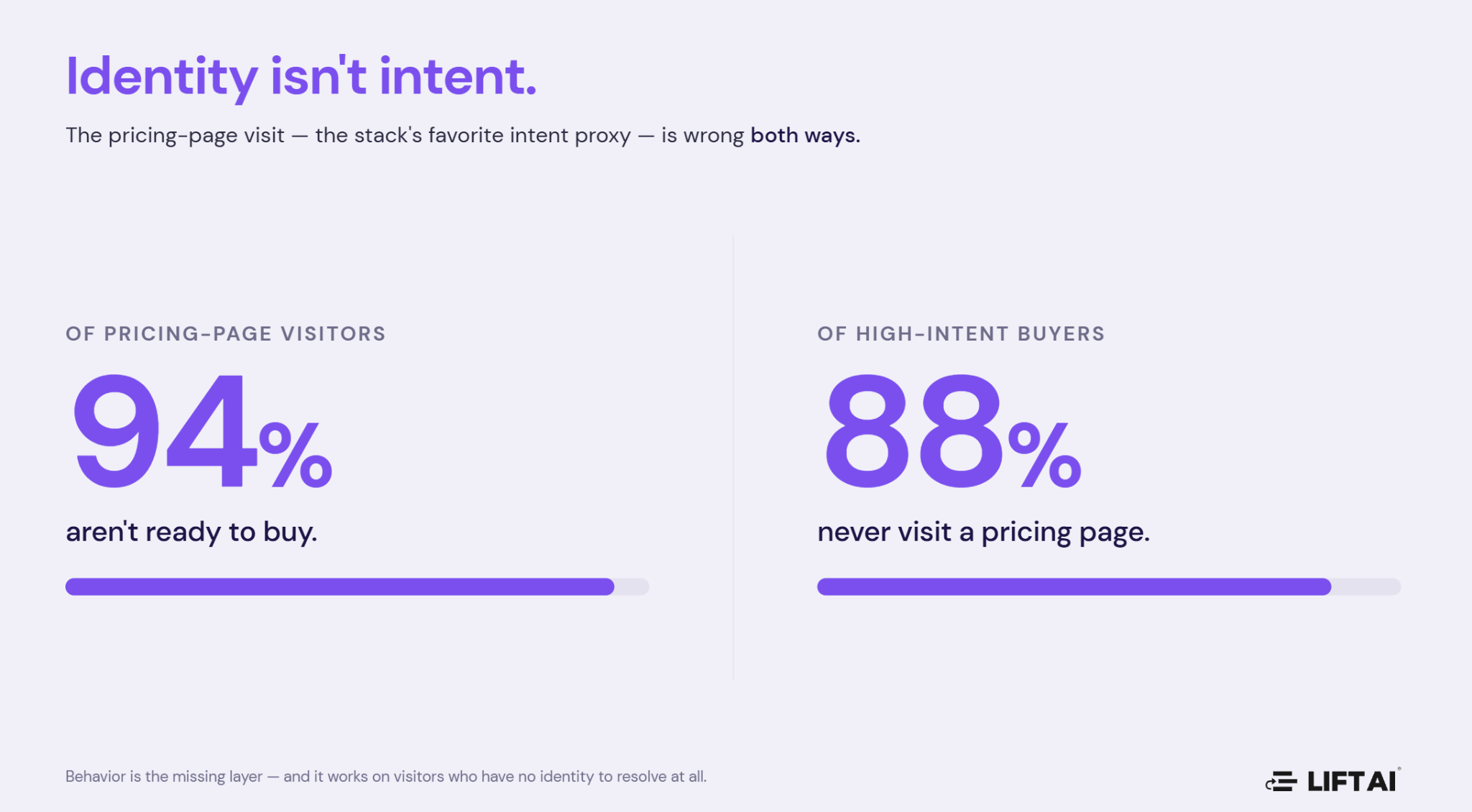
The first is that identity is a proxy for intent. A decade of investment and several large categories — identity resolution, enrichment, account intelligence, third-party intent — were built to answer “who is this visitor?” with ever greater precision. That work is valuable, and it is worth being precise here, because the lazy version of this argument overreaches: identity is not worthless, and the strongest systems combine identity and behavior rather than choosing between them. Identity tells you who to talk to and how to reach them. It is necessary infrastructure. But it is not sufficient, because it does not tell you whether to talk to them now and what kind of messaging to use. Knowing a visitor’s name, company, and ICP fit says nothing about whether they are ready to buy — which is why up to 94% of pricing-page visitors are not ready, and 88% of high probability buyers never visit a pricing page at all. Behavior is the missing predictive layer, and it has one property identity can never have: it works on the visitors who have no identity to resolve at all. The right architecture is behavioral probability layered on top of identity where identity exists, and standing on its own where it doesn’t.
The second assumption is that the visitors worth modeling are the ones you can identify. This is where the denominator gets interesting. It is trivially true that most website traffic is anonymous, so it would be unremarkable if most pipeline simply came from the larger pool. The non-trivial finding is that anonymous visitors with a high Website Buyer Probability Score convert at rates that rival or exceed identified ones. At Boomi, anonymous high-probability visitors converted to pipeline at 2.4× the rate of form fills. The implication is that a substantial, realizable pool of high-probability buyers sits in a population every identity-based system is structurally unable to score, prioritize, or engage — because those systems key off identity, and these visitors have none. The pipeline concentration follows: 85% of chat pipeline at Chronus, 58% at Boomi, 56% at Intelex, 54% at Payscale.
A vendor that trains on identity and engagement data inherits both blind spots. It learns from the wrong axis, and only from the 1–3% of visitors who raised a hand or ~30% who can be identified through other means. Its model is biased before the first epoch.
What modern AI does and doesn’t change about the data problem
It is fair to ask whether modern technique erases the data advantage. Foundation models, self-supervised and transfer learning, synthetic data, and entirely new signal streams — DOM structure, session graphs, mouse dynamics, in-session conversational context — have genuinely expanded the volume of usable signals and reduced how much labeled data a model needs to learn a useful representation. Anyone arguing that the 2005–2020 era was a permanently sealed golden age is overstating it; total usable signal has grown, not shrunk, and a good team today has tools a team in 2015 did not.
But there is a precise line these techniques do not cross. They learn representations; they do not manufacture ground-truth outcome labels. You can synthesize a plausible behavioral sequence. You cannot synthesize the fact that a specific visitor went on to generate audited, closed revenue. For a rare-event prediction problem, label fidelity is the binding constraint — the thing that determines whether the model is learning real buying or learning noise — and it is exactly the part that technique cannot conjure from nothing. Synthetic data and self-supervision raise the floor for everyone, which is good for the problem and good for buyers. They do not erase an advantage rooted in a large, clean, full-distribution set of verified outcomes. The model layer is getting better for everyone. The label layer is still earned.
The data that’s actually required to predict buying— and why the combination is rare
Most models learn from engagement. Lift AI learned from revenue. Predicting buying from website behavior requires a training set with a specific combination of properties, held together and accumulated over time. Each property is individually difficult to obtain. The combination is what’s rare.
Revenue-verified outcome labels. The labels a model learns from are the part that matters most, and most GTM data is labeled with CRM stages, MQL dispositions, or marketing-attributed outcomes — proxies that are noisy at best and circular at worst. Lift AI’s training labels are commission-audited revenue: outcomes proven to the decimal because real money changed hands on them, audited by enterprise clients whose own payouts depended on the accuracy. That is the cleanest class of label that exists for this problem.
The full behavioral distribution. The model was trained on the entire visitor population — buyers and the vast majority of non-buyers, anonymous and identified. A model that only sees the engaged minority never learns what the silent majority looks like, and so cannot score the anonymous population where much of the pipeline lives. Training on the full distribution is what makes scoring anonymous visitors possible at all.
Multi-industry coverage and continuity. The data spans industries and verticals, B2B and B2C, over fifteen years. Buying behavior has structural regularities that generalize across contexts, and breadth reduces the vertical bias a single-platform builder inherits from its own customer base.
This combination came from an unusual origin. From 2005 to 2020, Lift AI’s team operated a commission-based sales-as-a-service business — paid only when it correctly converted a visitor into revenue. That compensation structure is what produced audit-grade labels at scale across the full distribution: no incentive to mislabel, every incentive to capture everything. And because payment was tied to incremental revenue, the labels are causal-grade — proof that the engagement caused the outcome, not merely correlated with it. The result was billions of website journeys tied to hundreds of millions of commission-validated outcomes.

The honest framing of the moat is the durable one. The claim is not that this data can never be assembled by anyone — Google, Meta, Salesforce, HubSpot, and others sit on enormous behavioral datasets, and a determined, well-funded team could pursue something directionally similar over years. The claim is narrower and stronger: assembling this specific combination — full-distribution website behavior, linked to revenue-verified outcomes, across industries, with continuity — is exceptionally hard, and starting from it confers a head start measured in years rather than quarters. The largest data owners have scale but not this structure: their behavioral data is not linked to the full distribution of verified commercial outcomes in the way supervised buyer-probability modeling requires. Scale is not the same as fit.
Why the advantage is current, not archived
The sharpest challenge to a data-advantage thesis turns the continuous-learning defense against itself: if reinforcement keeps the model calibrated to current behavior, then within a few years the training distribution becomes majority-modern data — so the pre-degradation historical advantage dilutes. The challenge is correct on its own terms. It just mistakes what the moat is.
The moat was never “we hold old data others lack.” If it were, it would decay exactly as the challenge describes. The moat is that Lift AI operates a continuously-refreshed data pipeline with a structure competitors cannot easily reproduce even today: full-distribution website behavior linked to verified outcomes. The fifteen years did something specific and hard to replicate — they solved the cold-start problem. They gave the model a foundational understanding of how buying behavior maps to real outcomes, which is the single hardest thing to bootstrap when you are starting from zero verified labels. The ongoing pipeline is what sustains and extends that foundation. History is the head start. The data structure is the moat. The model becoming majority-current data over time is the design, not the flaw — it is how the advantage stays relevant while the cold-start barrier keeps protecting it.
Every Lift AI deployment generates first-party behavioral data unique to that customer and feeds the reinforcement loop, recalibrating against live production outcomes. Across the longest-running deployments, accuracy and F1 have stayed stable through exactly the behavioral shifts the challenge anticipates — changes in traffic mix, channel composition, and how buyers research. The foundation is the head start; the flywheel is why the head start tracks the present rather than aging into an archive.
The model performs — and it’s auditable
A data moat is worthless if the model it produces doesn’t work, so the performance is stated precisely and built to be verified rather than trusted.
Lift AI delivers a live Website Buyer Probability Score, 0–100, for every visitor — anonymous or known — in real time. Across deployments, the model achieves a median 85%+ accuracy, graded against what visitors actually did after being scored, not against a held-out benchmark. Because accuracy alone is misleading on imbalanced data, it is tracked alongside F1, which weights precision and recall equally; F1 consistently tracks the accuracy figure, confirming the model is right about both the rare buyers and the common non-buyers rather than defaulting to the majority class.
The operationally meaningful measure is separation. Across production deployments spanning B2B SaaS, B2B healthcare, B2C real estate, and B2C ecommerce — at scales from 60,000 to 8.1 million monthly visitors — the model concentrates a median 32% of all conversions into the top 12% of scored traffic, a median 22.6× conversion differential between high- and low-probability segments. And none of it is reported on trust: the full dashboard — confusion matrix, precision, recall, F1, concentration ratio, conversion differential, accuracy trend — updates daily in production with direct client access, available for independent audit at any time. The verifiability is part of the thesis. Most vendors ask buyers to accept a single accuracy number in a slide.
The proof that closes the loop
The strongest validation is what happens when a client routes a real commercial operation through the score.
Over an 18-month deployment, Boomi replaced page-based chat triggers with Lift AI’s probability scoring. Everything else held constant — same website, same sales team, no headcount change, no process overhaul. Conversational-AI-attributed revenue, measured through to closed-won deals, increased 23.4×.
That number is four compounding levers, not one. Probability-based triggers expanded the addressable engagement pool from 8.25% to 31.72% of visitors (+284%), by surfacing high-intent visitors page rules missed entirely. Engagement-to-opportunity rose from 3.6% to 5.4% (+50%). Opportunity-to-close moved from 5.4% to 14.2% (+163%) — a swing that normally requires sales-process change but here came purely from better opportunity quality. Average contract value rose 55%, because buyers found earlier are engaged before competitors frame the deal. The dashboard for the same deployment shows the origin: a 10.5× conversion differential at the top of the funnel, compounded through four downstream levers into the 23.4× revenue multiple at the bottom.
This is the thesis demonstrated end to end. Better outcome data produces a better probability model; a better model concentrates execution on the visitors most likely to convert; that concentration compounds through every downstream action into disproportionate revenue. The only thing that changed at Boomi was what the system paid attention to.
What this means for an investor
Strip the narrative to its load-bearing structure and the underwriting case is this.
Execution is commoditizing — models, agents, and workflows are converging and rentable, and the 5% ROI figure is the market’s evidence that execution alone produces no advantage. As execution commoditizes, the scarce, value-governing asset becomes the proprietary, outcome-linked data that decides where execution is applied. The market has already begun pricing this pattern into its largest GTM-adjacent acquisitions, where ownership of differentiated, decision-governing data — not execution capability — is the asset being bought.
Be precise about what competitors will and won’t do, because the credibility of the thesis depends on not overclaiming. They will close parts of the gap. A well-resourced Salesforce, HubSpot, or Intercom team can build directionally similar scoring inside its own ecosystem and reach “good enough” for many of its own customers without ever matching absolute accuracy. That is a real competitive and distribution dynamic, and it shapes go-to-market posture more than it threatens the thesis: the right response is to be the score inside those ecosystems — via protocol, integration, and partnership — rather than to fight their bundled version head-on. What is genuinely hard to close is the combination that produces accuracy and cross-industry generalization: full-distribution behavior, revenue-verified labels, multi-industry breadth, and the cold-start foundation that a team starting today cannot shortcut.
So the investment question is not “can anyone ever build this.” They can build toward it, and some will. The question is “who starts with the strongest position in the one layer that stays scarce as everything above it commoditizes — and does that position compound.” Lift AI’s answer rests on three claims, each defensible without hyperbole. The advantage is structural, not architectural: a rare, hard-to-assemble combination of data that confers a multi-year head start. It is current, not archived: a continuously-refreshed pipeline whose structure competitors can’t easily reproduce even now, with history as the cold-start barrier rather than the decaying core. And it is proven, not asserted: 85%+ production accuracy clients audit themselves, translating into a 23.4× closed-won revenue multiple in a controlled, single-variable deployment.
None of this requires believing the race is over, that no competitor can build anything similar, or that future innovation is irrelevant. It requires believing only what is almost certainly true: that better outcome-linked behavioral data produces better buyer-probability models, that Lift AI’s data combination is unusually strong and compounding, and that as execution becomes free, the signal underneath it becomes the asset worth owning. That is the layer Lift AI holds the strongest position in for website go-to-market — and the layer that gets more valuable, not less, as everything built on top of it commoditizes.
Lift AI is the Website Buyer Context layer for the GTM stack. It interprets each visitor's behavior in real time — known and anonymous — and resolves it into a Probability Score (0–100) that tells you how likely they are to buy, with over 85% accuracy.



